
Новая модель глубокого обучения, названная MelNet, может производить интонацию человека со сверхъестественной точностью. После тренировки он может восстановить голос любого человека за несколько секунд. Исследователи демонстрируют, насколько точно он может клонировать голос Билла Гейтса.
В последние годы были достигнуты огромные успехи в технике машинного обучения. Эти методы отлично сработали при распознавании объектов, лиц и создании реалистичных изображений.
Однако когда дело доходит до звука, искусственный интеллект вызывает разочарование. Даже самые лучшие системы преобразования текста в речь не имеют базовых функций, таких как изменения интонации. Вы слышали машинный голос Стивена Хокинга? Иногда становится очень трудно понять его предложения.
Теперь ученые из Facebook AI Research разработали метод, позволяющий преодолеть ограничения существующих систем преобразования текста в речь. Они создали генеративную модель, названную MelNet, которая может производить интонацию человека со сверхъестественной точностью. На самом деле, он может говорить свободно с чьим-либо голосом.
Чем MelNet отличается от существующей машинной речи?
Большинство алгоритмов глубокого обучения обучаются на больших аудио-базах данных, чтобы восстановить реальные речевые образцы. Основной проблемой этой методологии является тип данных. Как правило, эти алгоритмы обучаются на записи звуковых сигналов, которые имеют сложные структуры в резко изменяющихся временных масштабах.
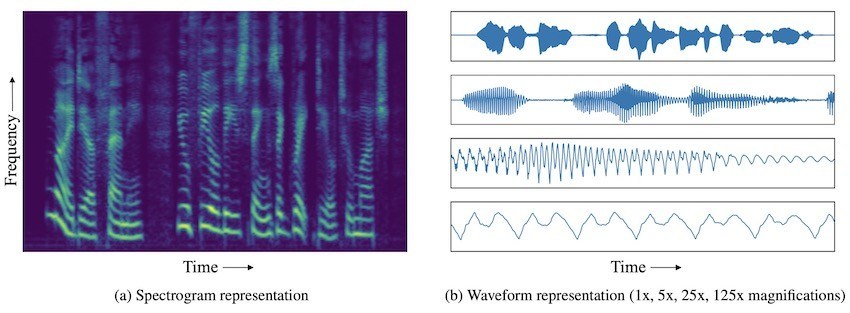
Эти записи показывают, как амплитуда звука изменяется со временем: одна секунда звука содержит десятки тысяч временных шагов. Такие осциллограммы отражают определенные закономерности в ряде различных масштабов.
Существующие генеративные модели сигналов (такие как SampleRNN и WaveNet) могут распространяться только через доли секунды. Поэтому они не могут захватить структуру высокого уровня, которая появляется в масштабе нескольких секунд.
MelNet, с другой стороны, использует спектрограммы (вместо звуковых сигналов) для обучения сетей глубокого обучения. Спектрограммы представляют собой двухмерные частотно-временные представления, которые показывают весь спектр звуковых частот и их изменение во времени.
В то время как одномерные сигналы во временной области фиксируют изменение во времени одной переменной (амплитуды), спектрограммы фиксируют изменение на разных частотах. Таким образом, аудиоинформация более плотно упакована в спектрограммы.
Это позволяет MelNet генерировать безоговорочные образцы речи и музыки с последовательностью в течение нескольких секунд. Он также способен к условной генерации речи и синтезу текста в речь, полностью сквозной.
Чтобы уменьшить потери информации и ограничить чрезмерное сглаживание, они смоделировали спектрограммы с высоким разрешением и использовали модель с высокой выразительностью авторегрессии, соответственно.
Исследователи обучили MelNet многочисленным беседам с Тедом, и затем он смог восстановить голос говорящего, произнесший случайные фразы в течение нескольких секунд. Ниже приведены два примера использования MelNet голоса Билла Гейтса для произнесения случайных фраз.
https://new-science.ru/wp-content/uploads/2019/07/Ai-Voice-2-port.mp3
“Port is a strong wine with a smoky taste.”
https://new-science.ru/wp-content/uploads/2019/07/Ai-voice-.mp3
“We frown when events take a bad turn.”
Больше примеров доступно на GitHub.
Хотя MelNet создает удивительно реалистичные аудиоклипы, он не может генерировать более длинные предложения или абзацы. Тем не менее система может улучшить взаимодействие между компьютером и человеком.
Многие разговоры о работе с клиентами включают короткие фразы. MelNet можно использовать для автоматизации таких взаимодействий или замены существующей автоматической голосовой системы для улучшения качества обслуживания абонентов.
Отрицательно то, что технология порождает призрак новой эры поддельного аудиоконтента. И, как и другие достижения в области искусственного интеллекта, он поднимает больше этических вопросов, чем ответов.
Источник:


